If you haven’t played the New York Times Spelling Bee puzzle before, I must say it is quite fun. Not fun enough to purchase an NYT subscription, but fun enough to automate the solution. Unfortunately, thanks to Wordle, my brain only thinks in five letter words now, and I’m quite rubbish at this puzzle. If you’ve never played the Spelling Bee puzzle, the rules are pretty simple.
How many words can you make with 7 letters?
Six letters are honeycombed around another letter. The letters provided and can be used multiple times, but the center letter MUST be used.
The Wordlist #
If you’re on a Linux distro, chances are you already have a solid wordlist on your system.
Checkout the
words (Unix) package.
On Debian/Ubuntu systems it’s located in /usr/share/dict/words.
This is true of my Arch install as well.
Also, if your locale is en_US then you can use the default path above.
As you follow the symlinks, you’ll see it points to ./words --> ./usa --> ./american-english.
This was important to learn when I was creating my
(8 Out of 10 Cats Does) Countdown Solver and needed to ensure I was using UK English.
If you’re on another system you’ll need to find another word list to use. Fortunately, Github is full of them.
Building the “One Liner” #
Start with using grep and its regular expression flag to find all acceptable words.
For illustrative purposes I’ll use the letters from today’s puzzle.
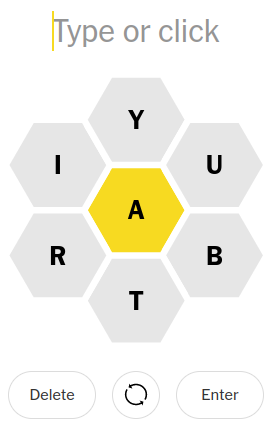
grep -iE '^[artyibua]{4,}+$' /usr/share/dict/words | grep -i a
In the above command, the regex is saying that from start (^) to finish ($), only find search when the following letters appear [artyibua]+.
To limit the search, I’ve added {4,} to only match on words that are four letters or more.
The puzzle does not accept words less than four letters long.
The final grep -i a is to ensure that the middle letter exists in the result set.
The next part is simply for aesthetics.
We’ll want to sort by the longest word descending.
To do that, we’ll use awk to print the length of the word along with the word itself, use sort to sort it by the numeric column, and finally use cut to remove the number from the output.
awk '{ print length, $0 }' # prints out each word in the format '6 rabbit'
sort -nrs # sort numerically, in reverse, and disable last-resort comparison
cut -d" " -f2 # split on [space] and print the second column from STDIN
The “one liner” in its full glory.
grep -iE '^[artyibua]{4,}+$' /usr/share/dict/words | grep -i a | awk '{ print length, $0 }' | sort -rns | cut -d" " -f2-
Putting it All Together in a Script #
I thew everything together in a small bash script and added a small usage function.
To get the regex in grep to evaluate properly, I had to use printf to get a proper format.
This way I can run ./spelling_bee.sh a yubtri and not shuffle through my ZSH history to find it every time.
It’s also kind of a pain to change both grep inputs.
#!/usr/bin/env bash
set -euo pipefail
usage() {
echo "usage: $0 [center] [outer]"
echo "example: $0 i wdehan"
}
# change if necessary
WORD_LIST="/usr/share/dict/words"
CENTER_CHAR=$1
OUTER_CHARS=$2
if [ -z "${CENTER_CHAR}" ] || [ -z "${OUTER_CHARS}" ]; then
usage
exit 1
fi
REGEXP=$(printf '^[%s%s]{4,}+$' "${CENTER_CHAR}" "${OUTER_CHARS}")
# do the good stuff
grep -iE "${REGEXP}" "${WORD_LIST}" | \
grep -i "${CENTER_CHAR}" | \
awk '{ print length, $0 }' | \
sort -nrs | \
cut -d" " -f2-